Link to my repository Link to complete GSOC blog
My 12 weeks of working for Redhen lab is finally coming to a conclusion. Here’s a brief summary of the work done and the challenges faced
Project Description
My project was to develop a stable pipeline that performs OCR on videos from Hindi and Bengali news channels. My goal was to automatically detect all pieces of text that appear in the video and saving the same in the expected Redhen format.
Process
I used EAST text detector for detecting the text from the videos. I have implemented the text detection in two parts. The first part involves detecting regions of text and then stitching together various detected regions to form words.
Since, the text detection is not language specific, it successfully detects text in all language.
NOTE: This functionality is a scalable solution for text detection that can be used for detecting text in any language from any video.
Example
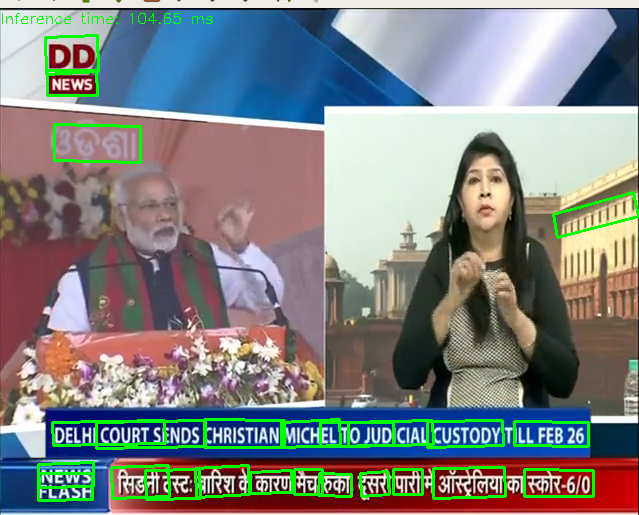
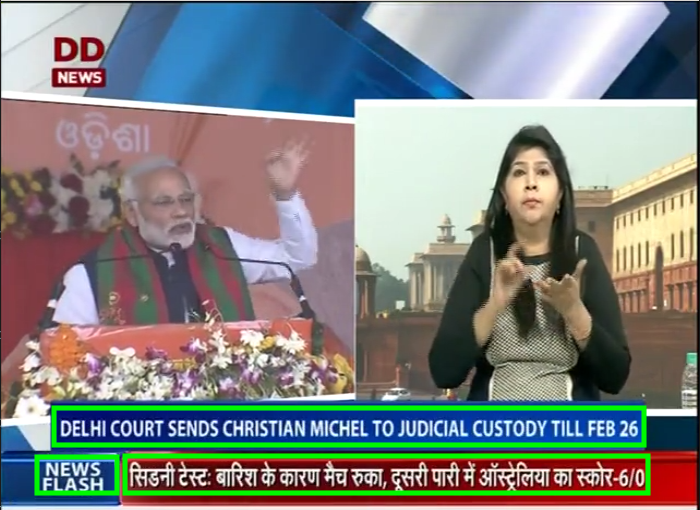
Code for text detection
The next phase of the project was OCR. I have implemented this functionality using Tesseract4.0. This proved to be the most challenging part of the project as I have implemented this for 3 diiferent languages
(bengali, hindi,english). Since there was no means of deducing the language of the detected text, I ran the OCR assuming the text to be in multiple languages. This has significantly decreased the accuracy in cases where a single sentence consisted of text in more than one language

OUTPUT: ‘HORITY द्वारा जनहित में जारी www.iepf.govin @’
Code for OCR
NOTE:The bengali OCR can be further improved to increase the accuracy
Here’s the final product
The final code is available at(https://github.com/Poulami-Sarkar/Bengali-Hindi-OCR/blob/master/textdetection.py). The code requires tesseract-OCR, language-pack-en and the python libraries pytesseract, opencv-python, numpy, pandas to be installed. This code can be run using:
python textdetection.py <video>.mp4 <directory path> '<language>'
The script takes 3 arguments.
- Filename of the video
- Full path of the directory containing the video and header file (This should be a text file with the same name as the video and extension .txt)
- OCR language ‘hin+eng’ or ‘ben’ for hindi or bengali news channels.
Run using singularity containers:
If you want to run the code without installing the prerequisite libraries you can opt for running it using singularity containers:
singularity exec -B `pwd`:/mnt ben-hin-ocr.sif python3 /mnt/textdetection.py <video>.mp4 <directory path> 'hin+eng'
For more details on how to run singualrity containers refer to this link1 link2
DEMO
Header file (2019-01-04_0500_IN_DD-News_News_For_Hearing_Impaired.txt):
TOP|20190104050001|2019-01-04_0500_IN_DD-News_News_For_Hearing_Impaired
COL|Communication Studies Archive, UCLA
UID|0b6fb8b0-3a42-11e9-9bda-cbebd1bc6130
DUR|00:29:54
VID|720x576|1024x576
SRC|Kolkata, India
TTL|Morning news
CMT|Morning news
CC1|HIN
LBT|2019-01-04 10:30:01 Asia/India
OUTPUT
TOP|20190104050001|2019-01-04_0500_IN_DD-News_News_For_Hearing_Impaired
COL|Communication Studies Archive, UCLA
UID|0b6fb8b0-3a42-11e9-9bda-cbebd1bc6130
DUR|00:29:54
VID|720x576|1024x576
SRC|Kolkata, India
TTL|Morning news
CMT|Morning news
CC1|HIN
LBT|2019-01-04 10:30:01 Asia/India
20190104050001.035|20190104050003.234|TIC2|000120|000 457 173 027|34 पैसे
20190104050004.703|20190104050006.902|TIC2|000230|999 464 999 021|उप
20190104050008.375|20190104050010.574|TIC2|000340|999 453 999 029|सिडनी टेस्ट ऋषभ पत ने शतक
20190104050012.043|20190104050014.246|TIC2|000450|040 455 464 027|पत ने शतक जड़ा. # सिडनी टेस्ट दोहरे शतक से
20190104050015.715|20190104050017.914|TIC2|000560|000 456 358 029|शतक से चके चेतेश्वर पुजारा, 193 रन पर हुए
20190104050019.387|20190104050021.586|TIC2|000670|000 456 404 032|हुए आउट. es उसस्ट्रेलिया ने भारत के खिलाफ
20190104050023.055|20190104050025.254|TIC2|000780|002 455 550 027|खिलाफ एकदिवसीय सीरीज के लिए 14 सदस्यीय टीम
20190104050026.727|20190104050028.926|TIC2|000890|000 454 210 029|टीम की घोषणा की. छ श्रीलंका के खिलाफ
20190104050030.395|20190104050032.598|TIC2|001000|014 454 438 032|के खिलाफ एकमात्र टी-20 के लिए टिम साउदी न्यजीलैंड
20190104050034.066|20190104050036.266|TIC2|001110|030 455 298 031|न्यूजीलैंड के कप्ान होंगे. # कतर ओपन:
....
....
....
0190104050008.374|20190104050010.574|OCR2|000330|225 421 194 020|DEKHO ZARAA SAR UTHAARAR
20190104050019.385|20190104050021.585|OCR2|000660|226 420 186 023|HAI SAARS KI DOR JAB TAR
20190104050030.396|20190104050120.310|OCR2|000990|046 064 051 022|NEWS
20190104050034.066|20190104050036.266|OCR2|001100|196 421 243 023|HONGE JUGRU SE ROSHAN KIS) OL GE:
20190104050041.407|20190104050043.607|OCR2|001320|178 421 277 022|0 538६ (5ि KE VAASTE CHALO ZETE HAN
20190104050045.077|20190104050047.277|OCR2|001430|178 421 278 021|HO SARE KTR KE VAASTE CHALO JEETE HAIN
20190104050048.747|20190104050050.947|OCR2|001540|180 421 278 022|HO SAKE KIS) KE VAASTE CHALO ZETE HAIN
20190104050052.418|20190104050054.618|OCR2|001650|180 421 276 022|HO SAKE KIS) KE VAASTE CHALO JEETE HAIN
20190104050056.088|20190104050105.629|OCR2|001980|200 420 238 022|CHALO JEETE HAIN CHALO JEETE HAIN
20190104050118.110|20190104050120.310|OCR2|002420|307 227 304 125||
20190104050129.121|20190104050134.991|OCR2|002750|149 219 341 063|क्रोध और असहिष्णुता सही
20190104050129.121|20190104050131.321|OCR2|002750|196 291 218 058|नि इन:
20190104050136.462|20190104050138.662|OCR2|002970|052 066 043 017|NEWS|
20190104050140.132|20190104050142.332|OCR2|003080|252 355 128 035|कि... alle पं गे
20190104050143.802|20190104050146.002|OCR2|003190|247 354 132 041|कं Ay ’ | की ? कक बी
20190104050202.154|20190104050204.354|OCR2|003740|221 287 323 036|205 POINTS & 33,614
20190104050205.824|20190104050208.024|OCR2|003850|332 094 231 025|FORMER FONEIGN SECRETARY
20190104050205.824|20190104050208.024|OCR2|003850|068 401 518 032|DEMOCRATS RETAKE CONTROL OF HOUSE;
20190104050205.824|20190104050208.024|OCR2|003850|192 036 299 033|US MIDTERM ELECTION
20190104050213.165|20190104050226.376|OCR2|004070|047 062 050 025|NEWS
20190104050216.835|20190104050219.035|OCR2|004180|101 414 471 025|ee न पीपल हुक ही COS one Ce a
20190104050216.835|20190104050219.035|OCR2|004180|257 376 153 025|बाच्द्ीय सगागार चैनल
20190104050231.517|20190104050233.717|OCR2|004620|174 262 101 019|HEADLINE
20190104050235.187|20190104050241.057|OCR2|004730|089 404 525 042|SC TO HEAR AYODHYA CASE
Submitting a slurm jobs on the HPC cluster
sbatch <filename>.slurm
The script used to submit the OCR code as a batch job can be found here
Submit the job using sbatch test.slurm
The maximum walltime for the main partition (queue) on the HPC server is 24 hours after which the job will automatically terminate. Since, my code is required to run periodically for new videos that are added to the server, I have made the job schedule itself before quitting.
This functionality can be disabled by commenting the line
sbatch test.slurm
as shown:
:
while [ 1 -eq 1 ]
do
NOW=$( date '+%T' )
if [ "$NOW" == "$TIME" ]
then
#sbatch trial.slurm
fi
done
echo 'exit'
Future scope
A major challenge was that poor image quality especially in Bengali news videos leads to some small errors.
[Example] Will be updated shortly
Other minor errors can be corrected using Natural Language Processing. Sentence completion and correction can be done using deeplearning (RNN). As a future project, this has to be implemented separately for each language as well as for any case of combination of two or more languages.
Links to the code
OCR
OCR training using tesseract
textdetection along with OCR
textdetection
Slurm HPC job (deployment)